机器学习交易过拟合怎么办?
机器学习中过拟合是非常常见的现象,尤其是量化交易中,来看看一些解决方法
常见时序模型防止过拟合方案
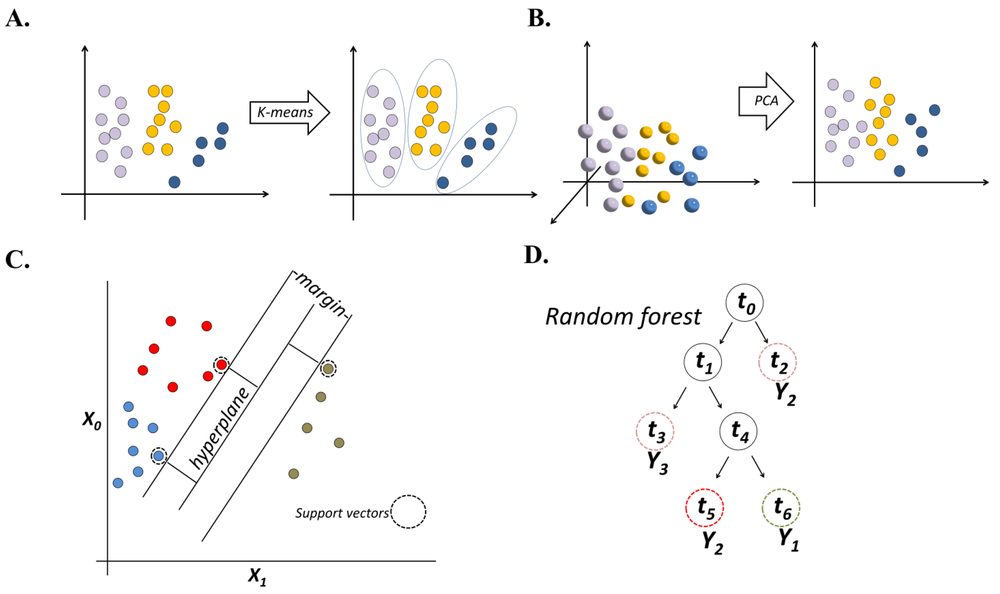
- 交叉验证(Cross-Validation):使用交叉验证可以评估模型在不同数据子集上的性能,从而减少过拟合的风险。常见的交叉验证方法包括K折交叉验证和留一交叉验证。通过在不同的训练集和验证集上训练和评估模型,可以更好地估计模型在未见过的数据上的表现。
- 正则化(Regularization):正则化是一种通过添加惩罚项来控制模型复杂度的方法。常用的正则化方法包括L1正则化(Lasso)和L2正则化(Ridge)。这些方法通过限制模型参数的大小,可以减少过拟合的风险。在量化交易中,正则化可以应用于线性模型、支持向量机等算法。
- 特征选择(Feature Selection):特征选择是选择对目标变量有最大预测能力的特征的过程。通过减少输入特征的数量,可以降低模型的复杂度,减少过拟合的风险。常见的特征选择方法包括相关系数、信息增益、L1正则化等。
- 集成学习(Ensemble Learning):集成学习是通过组合多个基本模型来提高整体性能的方法。常见的集成学习方法包括随机森林、梯度提升树等。集成学习可以减少模型的方差,并提高模型的泛化能力,从而降低过拟合的风险。
- Purged Group Time Series(PGTS):PGTS技术通过合理地处理训练和测试数据之间的时间关系,减少过拟合的风险。
本文将详细解释PGTS的原理和应用,并通过实例说明其在量化领域中的实际效果。
02
PGTS原理
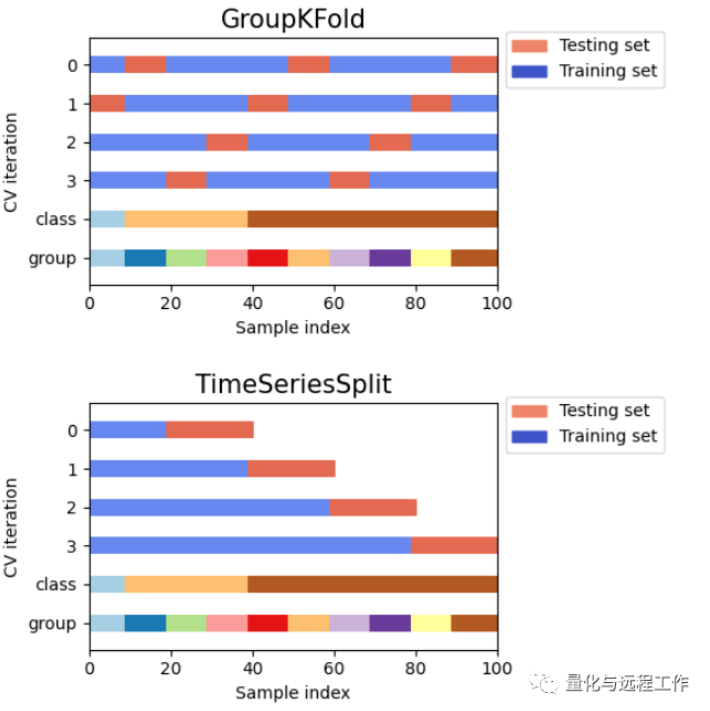
PGTS技术的核心思想是将训练数据分割成多个group,并确保每个group之间不存在时间重叠。在每个group中,模型只能使用之前的数据进行训练,而不能使用未来的数据。这种时间分割的方法可以更好地模拟实际应用中的情况,避免了模型在未来数据上过度拟合的问题。
假设我们有一组股票数据,其中包含每日的开盘价、收盘价、最高价和最低价。我们的目标是构建一个交易策略模型,根据过去的价格数据预测未来的涨跌情况。
首先,我们需要将数据分割成多个group,并确保每个group之间没有时间重叠。我们可以按照时间顺序将数据分成多个窗口,每个窗口包含一段连续的时间。例如,我们可以将数据分为5个窗口,每个窗口包含20天的数据。
然后,我们可以使用PGTS技术进行交叉验证。在每个窗口内,我们将使用之前的数据来训练模型,并在当前窗口内进行测试和评估。在训练模型时,我们需要确保不使用当前窗口及未来的数据。
PGTS代码
import pandas as pd
from sklearn.model_selection import GroupKFold
from sklearn.linear_model import LogisticRegression
# 加载股票数据
data = pd.read_csv('stock_data.csv')
# 定义特征和标签
X = data[['Open', 'Close', 'High', 'Low']]
y = data['Target']
# 定义分组信息(每个窗口为一个分组)
groups = data['Window']
# 定义PGTS函数
def purged_group_time_series(X, y, groups, n_splits=5, pct_embargo=0.1):
cv = GroupKFold(n_splits=n_splits)
embargos = pd.Series([pct_embargo] * len(groups))
preds, trues = [], []
for train_index, test_index in cv.split(X, y, groups):
train_embargo = int(embargos[train_index].max())
test_embargo = int(embargos[test_index].max())
X_train = X.iloc[train_index]
y_train = y.iloc[train_index]
X_test = X.iloc[test_index]
y_test = y.iloc[test_index]
# 去除测试集中的embargo期间的数据
test_cut = X_test.index < X_test.index[0] + test_embargo
X_test = X_test[test_cut]
y_test = y_test[test_cut]
# 在训练集上训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
preds.extend(y_pred)
trues.extend(y_test)
return preds, trues
# 初始化模型
model = LogisticRegression()
# 使用PGTS进行交叉验证
preds, trues = purged_group_time_series(X, y, groups)
# 计算模型的性能指标,例如准确率、召回率等
accuracy = (preds == trues).mean()
PGTS和上面提到的各种方法也不能完全解决过拟合,我们不可完全依赖机器学习,对市场和模型我们要有自己的建模和认知。Thanks!

